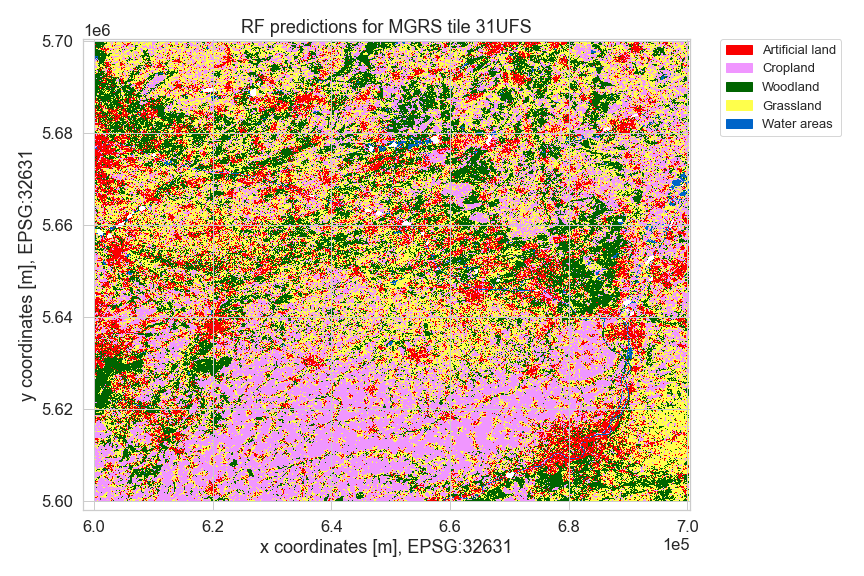
# Dynamic land cover service
In this notebook we will be studying land cover mapping. Land cover mapping has been done since the onset of remote sensing, and LC products have been identified as a fundamental variable needed for studying the functional and morphological changes occurring in the Earth's ecosystems and the environment, and plays therefore an important role in studying climate change and carbon circulation (Congalton et al., 2014; Feddema et al., 2005; Sellers et al., 1997). In addition to that, it provides valuable information for policy development and a wide range of applications within natural sciences and life sciences, making it one of the most widely studied applications within remote sensing (Yu et al., 2014, Tucker et al., 1985; Running, 2008; Yang et al., 2013).
With this variety in application fields comes a variety of user needs. Depending on the use case, there may be large differences in the target labels desired, the target year(s) requested, the output resolution needed, the featureset used, the stratification strategy employed, and more. The goal of this use case is to show that OpenEO as a platform can deal with this variability, and we will do so through creating a userfriendly interface in which the user can set a variety of parameters that will tailor the pipeline from -reference set & L2A+GRD > to model > to inference- to the users needs.
In this notebook, helper functionality from this repository (opens new window) is used. It contains amongst others the entire feature building engineering workflow, so if you are interested in knowing how to do that or if you want to make more customizations towards your own use case, have a look at it. Note that the repository is not finalized, as it is a general repository also used for other purposes.
A full notebook for this use case can be found here (opens new window).
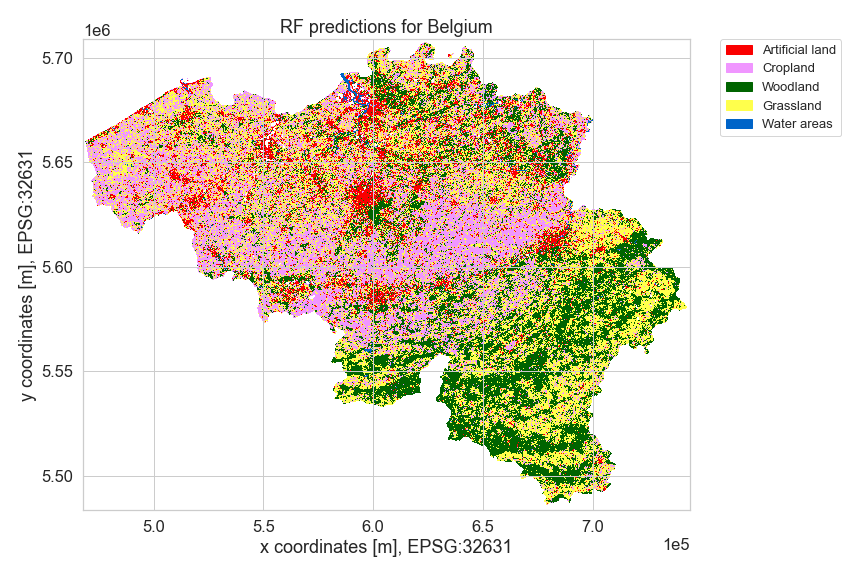
# Methodology
# Reference data
The reference dataset used in this section is the Land Use/Cover Area frame Survey (LUCAS) Copernicus dataset of 2018. LUCAS is an evenly spaced in-situ land use and land cover ground survey exercise that extends over the entire of the European Union. The Copernicus module extends up to 51m in four cardinal directions to delineate polygons for each of these points. The final product contains about 60,000 polygons, from which subsequent points can be sampled (d'Andrimont et al., 2021). You as a user can specify how many points to sample from these polygons to train your model. In addition, the user can upload extra target data to improve performance.
# Input data
The service created runs on features constructed from GRD sigma0 and L2A data. This data will be accessed through OpenEO platform from Terrascope and Sentinel Hub. You, as a user, can determine a time range, though the year should be kept to 2018, as that is the year in which the LUCAS Copernicus dataset was assembled. Data from other years can be extracted for prediction, provided that the user uploads their own reference set.
# Preprocessing
The L2A data has been masked using the sen2cor sceneclassification, with a buffering approach developed at VITO and made available as a process called mask_scl_dilation. From the Sentinel-1 GRD collection, backscatter is calculated.
# Feature engineering
We select and calculate the following products from our input collections:
- 7 indices (NDVI, NDMI, NDGI, ANIR, NDRE1, NDRE2, NDRE5) and 2 bands (B06, B12) from the L2A collection
- VV, VH and VV/VH (ratio) from the GRD sigma0 collection
All layers are rescaled to 0 to 30000 for computational efficiency. The indices/bands are then aggregated temporally (for Sentinel-2 data: 10-day window using the median. For Sentinel-1 data: 12 day window using the mean. The median was used for the S2 collection instead of the mean to prevent possible artifacts caused by cloud shadows). The output is then interpolated linearly and the S1 cube is resampled spatially to a 10m resolution. Finally, 10 features are calculated on each of the band dimensions. These 10 features are the standard deviation, 25th, 50th and 75th percentile, and 6 equidistant t-steps. Through this procedure, we end up with a total of 120 features (12 bands x 10 features).
# Model
Where previously models had to be trained outside of openEO, we can now train Random Forest models in openEO itself. Hyperparameter tuning can be performed using a custom hyperparameter set. After training, the model is validated and used for prediction.
# Implementation
First, we load in a dataset with target labels. In order for the model to work, the target labels need to be integers. Also, we extract some target points from the target polygons.
Next, we will create our featureset and use this featureset to train a model. The indices from which you calculate features can be adjusted by a parameter, but if you'd want you could even create the entire feature engineering pipeline yourself. If you are interested in knowing how to do so, you can dive a little bit deeper into the openEO code found here (opens new window).
Subsequently, we can calculate a number of validation metrics from our test set. To do so, we do inference for the points of our y-test set and write these predictions out to a netCDF. The function calculate_validation_metrics (not part of openEO itself, but simply a client-side helper function) then loads in the y-test geojson and the netCDF with predicted values, extracts the points and stores the predicted values alongside their actual target labels in a dataframe.
After inspecting the metrics and possibly further finetuning the model or dataset, we can do inference on an area of choice and write the result. Happy mapping!